MongoDB高可用
单节点
分析:
- 由于单节点,读写均在一个节点上进行,读写压力可能比较大
- 存在单点故障问题,一旦出现问题,整个服务都不用
- 存储的数据量也会成为一个瓶颈
优点:
- 结构简单,已部署,已维护,客户端使用起来也方便
主从架构
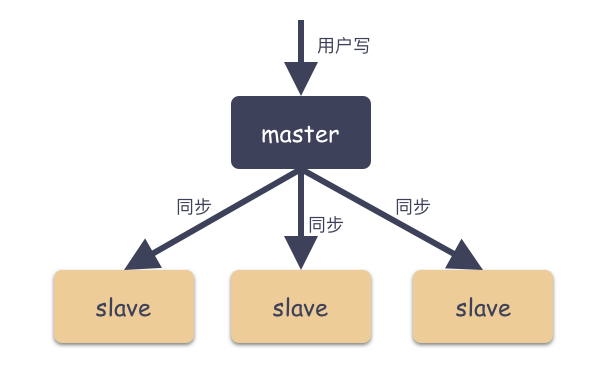
特点:
- 写数据只能在master上进行
- slave之间互相不能感知
分析:
- 存在主从必定存在数据复制的过程,那么逃不了要面临数据同步延迟问题,也就是数据不一致问题
- 如果master宕机后正好数据同步不及时,那么数据就会丢失
- 由于slave之间不能互相感知,并且又没有另外的类似监控角色存在,所以一旦master宕机,是没办法自动故障转移的,必须人为参与,那么SLA(就是指几个9,或者可用性)必定大打折扣
从MongoDB 3.6 开始已经彻底废弃不使用了
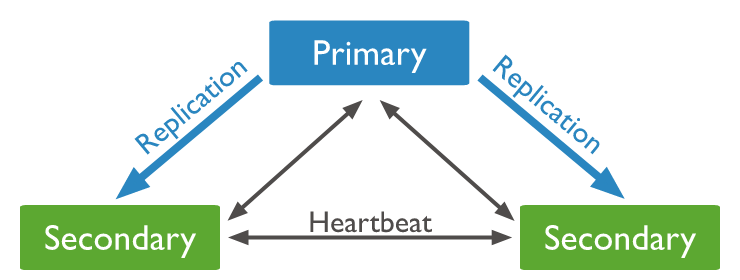
副本集架构
- 有三种角色:Primary,Secondary,Arbiter(可选),下面可能会描述为主节点(Primary)、从节点(Secondary)
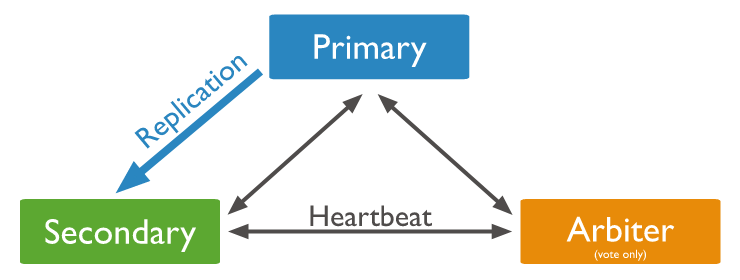
- Arbiter不储存数据,只负责投票,并且是可选配置
- Primary节点有且仅有一个
- 在某些特定场合(比如网络出现分区),Primary节点可能出现多个,但通常只有最新的primary节点能正常响应写请求
- Primary会把对数据的所有改动都记录在oplog日志中
- 从节点会同步primary节点的oplog,然后根据oplog进行重放,从而保持与Primary数据同步
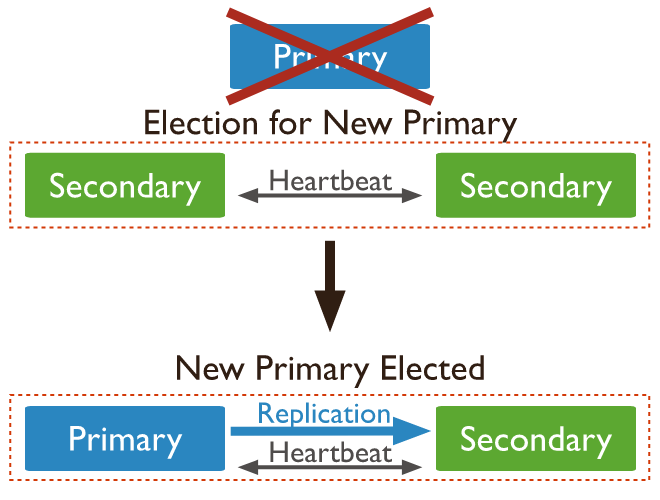
- 如果某个时候Primary节点不可用,那么从节点会发起选举要求自己成为主节点
- 在某个情况下(比如成本限制)没有条件部署多余的从节点,此时可以选择部署一个Arbiter,Arbiter只复制选举,不负责数据存储。通过这样的方式既能节约成本,又能保证高可用。比如注意观察下面的图
- 当主节点生产oplog的速率大于从节点复制oplog的速率,那么数据延迟会逐渐增长。当超过一个阈值后,主节点会开启流量控制。
- 主节点流量控制:一言蔽之就是主节点会限制应用写入数据的速度。如何限制呢? 当主节点开启流控后,应用写入数据前需先请求一个票据(可以理解为token),主节点通过限制票据的生产速度来达到流控的目的
- 当从节点与主节点断开联系超过一定的时间,那么符合条件的从节点会发起选举要求自己成为主节点
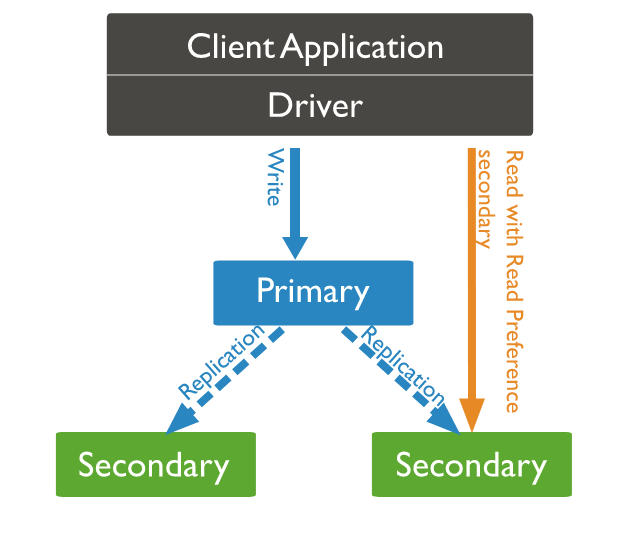
- 副本集群在选主过程中,是不能对外提供写服务的(这是一种不可用的表现),但保留了提供读服务的能力。(用不用取决于客户端,客户端可以配置在主节点脱机时是否在从节点上执行)
- 默认情况下,客户端的读操作由主节点完成。但客户端可以通过配置从而让从节点来完成读操作
- 下面的图全部来自于mongodb官网
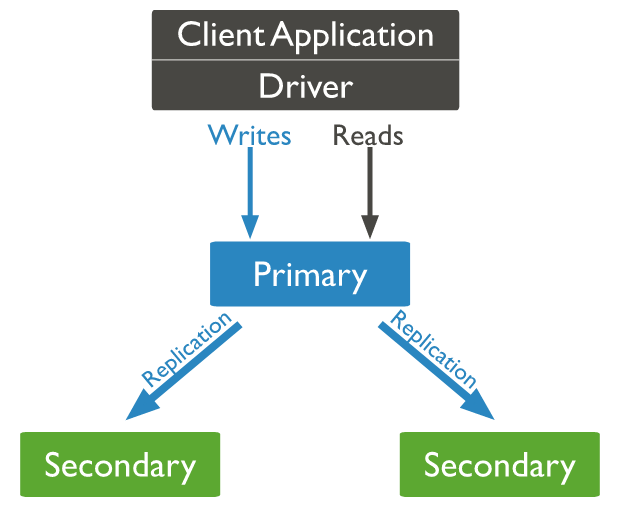
本质也是主从架构,只是增加了第三个角色:仲裁者(Arbiter),然后更换了角色名以及职责
扩展阅读:https://www.mongodb.com/docs/manual/replication/
特点:
- primary节点负责读写请求的处理(客户端可以指定把读请求交给副本节点完成)
- 整个集群中,各个节点之间有心跳信息,也就是说从节点间能互相感知
- primary节点宕机后,会从seondary节点中选择一个作为新的primay节点对外提供服务
- arbiter节点不存储数据,只进行选主投票
分析:
- 通过增加仲裁者的角色以及节点间互相感知的功能,可以做到故障自动转移
- 仍然存在数据不一致或丢失的问题
- 随机毒鸡汤:别羡慕他们,他们也会分的。