MySQL锁、事务、隔离级别
MySQL分区表
这部分内容请移步:MySQL分区表
采用这种方式对表进行分区,只能扩大表的存储条数,在性能提升上没有多大意义。
所以分表一般也要分库(部署在不同的数据库实例上)
InnoDB锁
这个章节主要包括下面几个方面:
- 共享锁和排它锁
- 意向锁(Intention Locks)
- 行锁(Record Locks)
- 间隙锁(Gap Locks)
- next-key lock (gap lock + record lock。)(2022年9月8号注释:next-key lock=gap lock + record lock,这个说法记得貌似在官网上看到的,并且没有过多的解释)
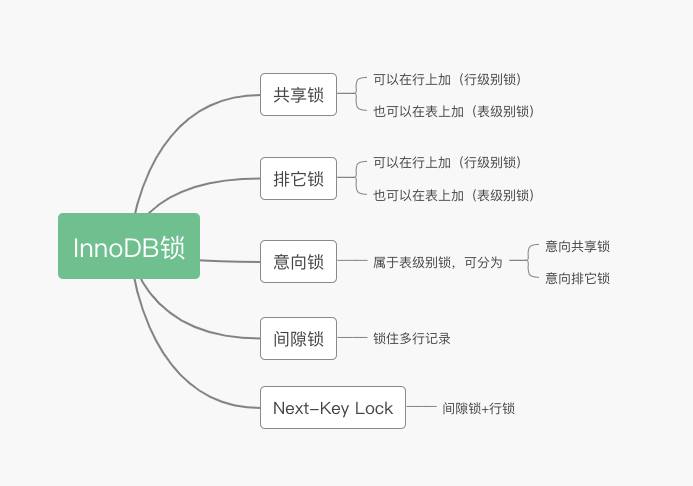
共享锁和排它锁
共享锁也称读锁,排它锁也称写锁。
共享锁可以添加到表上,也可以添加到某些行上。 排它锁可以添加到表上,也可以添加到某些行上。 所以这两种锁既可以是表锁,也可以是行锁
给表加 共享锁 (注意:不是意向共享锁)
lock tables 表名 read
给表加 排它锁 (注意:不是意向排它锁)
lock tables 表名 write
取消表锁(包括共享锁、排它锁)
unlock tables
如果一个事务对某些行加了共享锁,这个时候如果其他事务再次对相同行申请共享锁则可以立即获得共享锁。但如果对相同行申请排它锁,则不能立即获得排它锁
这两个锁没啥好讲的,MySQL官方手册也是这样讲的。参考:MySQL官方手册
意向锁
InnoDB支持多种粒度的锁,也就是锁InnoDB允许行锁和表锁并存。
意向锁是表级别的锁,表示事务稍后要申请哪种类型的行锁。
意向锁有两种:
- 意向共享锁(IS):表示事务稍后需要在某些行上申请共享锁
- 意向排它锁(IX):表示事务稍后需要在某些行上申请排它锁
InnoDB要求:
- 事务在某些行上获得共享锁前必须先获得意向共享锁
- 事务在某些行上获得排它锁前必须先获得意向排他锁
添加意向共享锁
SELECT ... LOCK IN SHARE MODE
添加意向排它锁
SELECT ... FOR UPDATE
表级别锁兼容性矩阵:
| X | IX | S | IS | |
|---|---|---|---|---|
| X | Conflict | Conflict | Conflict | Conflict |
| IX | Conflict | Compatible | Conflict | Compatible |
| S | Conflict | Conflict | Compatible | Compatible |
| IS | Conflict | Compatible | Compatible | Compatible |
- X与任和锁都不兼容
- S与带X的锁都不兼容
- I和I互相兼容
Intention locks do not block anything except full table requests (for example, LOCK TABLES … WRITE)
间隙锁
间隙锁就是锁一个范围的记录。比如 select … where c between 10 and 20 for update, 那么如果有其他事务想要插入一个c字段为15的记录则需要等待(无论这个值是否存在)。
可重复读隔离级别下是如何解决幻读问题
mysql在可重复读隔离级别下已经解决了幻读问题(这一点是确认了的),那么是如何解决的呢?
下面的讨论基于repeatable-read隔离级别:
select ... from xxxx
因为在repeatable-read隔离级别,所以上面的语句是一致性读,不会加锁,也没有间隙锁,多次执行都是读的快照数据,所以相同,不存在幻读问题
对于锁定读(lock in share mode 或者 for update)和update/delete语句
- 如果语句使用了唯一索引(主键也是唯一索引),则只会对那一条记录上锁,也就是行锁,没有间隙锁。既然有行锁了,那么其他事务肯定不能修改、删除这条数据,也不能插入(假设where条件中的数据不存在)
- 否则,会加间隙锁(具体针对哪些范围加间隙锁还搞不懂)
比如:
- 如果where语句使用了唯一性索引(主键也是唯一性索引),但使用了范围条件,会对指定范围加间隙锁(即:其他事务在指定范围内不能插入数据)。
也就是说其他事务可以在非锁定范围插入数据,
也就是说之前加间隙锁的事务如果把select的范围加大是能看到刚才其他事务插入的数据的。(这个结论已经经过实验论证了)
- 如果没有使用where语句,会对整张表加间隙锁(即:其他事务不能插入任何数据)
总结:也就是说如果语句不能唯一确定一条记录,则会加上间隙锁。
注意:lock in share mode == for share
间隙锁允许不同的事务将冲突的锁保持在间隙上。例如,事务A可以在间隙上保留一个共享的间隙锁(间隙S锁),而事务B可以在同一间隙上保留排他的间隙锁(间隙X锁)。 如下三个事务都能成功上锁(就是I和I互相兼容):
事务A:
start transaction ;
select * from test where id >= 1 and id < 4 lock in share mode ;
事务B:
start transaction ;
select * from test where id >= 1 and id < 4 for update ;
事务C:
start transaction ;
select * from test where id >= 1 and id < 4 lock in share mode ;
可以通过show engine innodb status查看锁信息,需要先执行:
set GLOBAL innodb_status_output=ON;
set global innodb_status_output_locks = on
间隙锁的唯一目的是防止其他事务插入、修改间隙 ,其他事务也不能对在间隙锁范围的数据进行修改
其他锁
请参考官方手册:
https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-locks-set.html
事务
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
注意:mysql的事务是在同一个实例中有效,即便是操作不同库的数据也可以。比如:
start transaction ;
update laijiandu_prod.ljd_user set nick_name = '夏沫xxx' where uid = 3939;
update laijiandu.ljd_user set nick_name = '空鸿宇zxx' where uid = 7;
select * from laijiandu_prod.ljd_user where uid = 3939;
select * from laijiandu.ljd_user where uid = 7;
//这个回滚是可以的
rollback ;
事务隔离级别的作用域分为 全局 和 当前回话,可以动态更改。
set @@global.tx_isolation='repeatable-read';
select @@global.tx_isolation;
set @@session.tx_isolation = 'read-committed';
select @@session.tx_isolation;
使用方法
-- 事务开启
START TRANSACTION; 或者 BEGIN;
开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句,不包括DDL语句。
-- 事务提交
COMMIT;
-- 事务回滚
ROLLBACK;
如果部分操作发生问题,映射到事务开启前
-- 保存点
设置一个事务保存点: SAVEPOINT 保存点名称
回滚到保存点: ROLLBACK TO SAVEPOINT 保存点名称
删除保存点: RELEASE SAVEPOINT 保存点名称
同一个扁平事务中可以有多个savepoint,如果名字相同可以覆盖,之前相同名字的savepoint则失效
SET autocommit 与 START TRANSACTION的区别
- SET autocommit 当前连接中有效
- START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务)
四个特性ACID
注意zk有个cap理论,注意区分acid和cap
事务的这四个特性并不代表每个事务都拥有这四个特性,这要看事务隔离级别的设置。 在MySQL中,当事务隔离级别设置为REPEATABLE-READ或者SERIALIZABLE的时候才满足隔离性这个要求
MySQL事务不能被嵌套,所以Spring框架中的嵌套事务是假的嵌套事务
原子性 A
Atomicity:是指同一个事务中的所有操作,要么全成功,要么全失败,是不可分割的工作单位
一致性 C
Consistency:是指事务将数据库从一种一致性状态转换为另外一种一致性状态。事务开始前和结束后,数据库的完整性约束没有被破坏。只会存在两种状态:事务提交前的状态 和 事务提交后的状态,不会存在中间态(比如:事务提交前是 AAA,
现在事务要改成BBB,那么一致性就要求数据只能是AAA,BBB这两种状态,不能是BAA的状态)。
隔离性 I
Isolation:事务提交提交之前,相互之间不可见,分了四种等级
持久性 D
Durability:事务成功提交之后,其结果是持久的。即便发送宕机等事故,数据库也能将数据恢复。
不考虑隔离性可能产生的问题
脏读
脏读:另一个事务还没提交的数据也能读到
不可重复读
幻读
隔离级别是可重复读,在一个事务中前后两次相同的查询,查到了其他事务insert进来的数据。
事务隔离级别与MVCC
| 隔离级别 | 别名 | 描述 |
|---|---|---|
| READ UNCOMMITTED (读未提交) | dirty read (脏读) | 另一个事务还没提交的数据也能读到 |
| READ COMMITED (读已提交) | unrepeatable read (不可重复读) | 只有已经提交的数据才能被读取到,但是可能存在同一个事务中的两个相同的select语句执行后拿到的数据不一致的情况,因此称作不可重复读 |
| REPEATABLE READ (可重复读) | 只会读取已提交数据,同一个事务中两个相同的select语句执行结果是一致的。在第一次读取的时候会产生一个数据库快照,以后该事务中的所有读操作其实都是读取的这个快照 | |
| SERIALIZABLE (可序列化) | This level is like REPEATABLE READ, but InnoDB implicitly converts all plain SELECT statements to SELECT … LOCK IN SHARE MODE if autocommit is disabled (这个隔离级别和可重复度很相似,只是mysql会在禁用autocommit的时候,自动把所有的select 语句都转换为 lock in share mode的形式。因此在这个隔离级别下一致性非锁定读也就不再给予支持了,所以mvcc在这个隔离级别下就不工作了) |
幻读是如何解决的?
在可重复读隔离级别下
- 如果采用的是一致性非锁定读(也就是select 后面没有for update也没有lock in share
mode),mysql读取的是事务开始时候的那个版本数据,所以达到了可重复读的效果。但是在当前事务自己delete或者update了数据,那么两次select的结果是不一样的。 - 如果采用的是一致性锁定读(也就是select后面跟着有 for update 或者 lock in share mode),针对这种情况,mysql是通过next-key
lock(也就是行锁和间隙锁)来达到可重复读的效果的。(如果锁定读能锁定唯一一行记录,则mysql加的是行锁,否则加的就是间隙锁)
MVCC
-
最大的作用是: 实现了非阻塞的读操作,写操作也只锁定了必要的行.
-
MYSQL的MVCC 只在 read committed 和 repeatable read 2个隔离级别下工作.
-
MVCC参与工作的时候,默认情况下使用的是一致性非锁定读。
-
一致性非锁定读:读取快照数据。read-committed读取最新版本数据,repeatable-read读取第一次select时候的版本数据(不是执行 start transaction的执行,可实验得知)
-
一致性锁定读:对读取的数据会进行加锁操作
select ... for update; 意向排它锁+(行锁或间隙锁) select ... lock in share mode; 意向共享锁+(行锁或间隙锁) -
是通过undo log来实现的
事务隔离级别实现原理
总的来说,是通过mvcc以及next-key锁来完成的。
针对读未提交
这个可以理解没有没有隔离,每次读取都是读的最新数据,不管事务是否提交
针对读提交
读提交的实现要依赖于mvcc以及readview了。 innodb在修改数据的时候,生成undo log,并且会生成一个undo
log的版本控制链。这个控制链可以理解为一个单向链表,链表中的每个节点有几个关键属性:值是多少,修改这个值的事务id,以及下一个节点的指针(这个节点的具体表现形式就是undo log)
然后介绍下readview,这个readview包含几个关键信息:
- m_ids : 代表创建这个readview时活跃的事务id集合
- min_trx_id: 代表m_ids中最小的一个
- max_trx_id: 代表的是下一个等待分配的事务id,并不是m_ids中最大的那个
- creator_trx_id: 代表的是创建这个readview的事务id
根据readview的信息,当事务读取数据的时候,从这个链表的第一个节点开始读, 如果这个节点中的事务id和当前事务的id一样,说这个修改是当前事务自己修改的,则取当前节点的数值。
如果不一样,则判断这个节点的事务id是不在m_ids中,如果在,说明是其他活跃事务修改的,则不取这个节点的数值,并读取下一个节点。 如果这个节点的事务id不在m_ids中,则说明这个事务id已经完成,则取这个节点的数据。
有了上面的版本控制链以及readview后,就可以来介绍读提交的实现原理了。
在读提交隔离级别下,每次查询操作,都会生成一个新的readview. (这很关键)
假设现在有两个事务A,B,对应的事务id分别是1,2 事务A先执行了一个select操作,这个时候会创建一个readview,此时根据readview的读取流程会读到一个值,假设是A.
这个时候事务B开始了,并且把值改为了B,于是现在的控制链就是,头结点的值是B,事务id是2,然后指向后一个节点。
这个时候事务A再一次执行select操作(假设事务B还未提交),于是又会创建一个readview,这个readview的m_ids就有1,2. 然后发现头结点的事务id是2,不是
自己的这个事务id,然后又在m_ids中,于是就会读取下一个节点的数据。最终还是读到了A。 然后这个时候事务B进行了提交操作。 然后事务A在执行,又会创建一个新的readview,但这个时候m_ids中就没有2.
于是读取到头结点中的事务id是2,然后不是自己这个事务,并且也不在m_ids中,于是乎就读到了B
针对可重复读
其实也依赖于控制链和readview,同时还依赖于了next-key锁 在这个隔离级别下,只会在首次select的时候才会创建readview,根据readview对控制链的读取过程就知道,
这个限制就相当于固定了读取的版本了所以达到了可重复读的效果
同时在这个隔离级别下页解决了幻读的问题: 如果执行的select没有lock in share mode或者for update语句,则是根据刚才说的readview来实现了可重复读,也就是我们说的一致性非锁定读
如果执行的有这两个,这个时候又分两种情况:
- 如果这个select从理论上能唯一定位一行记录,也就是用到了唯一索引或者主键索引,则mysql会对这行记录加行锁,这样其他事务就不能进行相关修改操作
- 如果不能唯一定位一行记录,则会对相关记录加间隙锁,这样其他事务就不能在这个范围插入、删除记录,已达到解决幻读的目的
分库分表
常用中间件:MyCat ShardingJdbc(推荐)
一张表超过多少条数据就可以分表了?
其实这个说法我个人持保留观点,要不要看到网上讨论这个或者听到同事说超过多少多少条mysql就撑不住了之类的结论,这个我个人持保留观点。为啥子,因为我自己曾经实打实的接触过一张表里有1亿8千万条数据的情况,不开玩笑,但我们查任意一页的时候,都是秒返。但是我们这里分页方式是做了优化的,就是采用断点分页。如果采用普通的limit
?,?方式是有影响的。所以我的观点是,对于多少条记录要看使用场景和使用方式。
分布式事务
分库分表后,不可避免的需要考虑分布式事务 常用中间件:Seata
MySQL数据库规范
具体参见:
https://snailclimb.gitee.io/javaguide/#/docs/database/MySQL%E9%AB%98%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E8%A7%84%E8%8C%83%E5%BB%BA%E8%AE%AE
阿里巴巴对数据库相关的约束
事务的分类
-
扁平事务
-
带保存点的事务
-
链事务
-
嵌套事务
-
分布式事务
杂项
-
一张表无论有多少个索引,在同一个where条件中,最多只能使用这张表的一个索引(但是where语句还可以使用其他表的索引)
-
小表驱动大表:比如最终只需要筛选10条数据,应该尽量先把这10数据的标识字段筛选出来,然后再去关联取出其他相关数据(这种对小表驱动大表的理解是错误,但解释本身是具有参考意义的,具体的小表驱动大表相关知识见 小表驱动大表.md)
-
可以通过explain方法查看sql语句的执行情况 using filesort : 排序数量较小的情况下才可接受
-
对is_del字段添加索引(只有两个值:0、1),效果大吗? 不大
-
单张表的存储大小限制不受mysql本身限制,而是受 操作系统 的限制。
Operating System File-size Limit Win32 w/ FAT/FAT32 2GB/4GB Win32 w/ NTFS 2TB (possibly larger) Linux 2.2-Intel 32-bit 2GB (LFS: 4GB) Linux 2.4+ (using ext3 file system) 4TB Solaris 9/10 16TB OS X w/ HFS+ 2TB The effective maximum table size for MySQL databases is usually determined by operating system constraints on file sizes, not by MySQL internal limits. -
information_schema库中的tables表 查看单张表占用的物理空间大小
select (data_length+index_length)/1024/1024/1024 as datasize_gb from tables where table_schema = 'fotoplacedb2' and table_name = 'usermessage'; +----------------+ | datasize_gb | +----------------+ | 8.026367187500 | +----------------+ 1 row in set (0.02 sec) -
usermessage表(1亿8千万条数据),如果按照主键mgsId来分页,完全不用考虑速度的问题。
select * from usermessage where msgid < 94956539 order by msgid desc limit 10; O.OO sec select * from usermessage where msgid < 94956539 order by msgid asc limit 10; 0.00 sec select * from usermessage where msgid < 174956539 order by msgid desc limit 10; 0.00 sec select * from usermessage where msgid < 100 order by msgid desc limit 10; 0.00 sec -
mysql 数据存储方式
- 共享表空间
Innodb的所有数据保存在同一个表空间里面,这个表空间可以由很多个文件组成,一个表可以跨多个文件存在。 所以其大小限制不再是文件大小的限制,而是其自身的限制。 从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单 表限制基本上也在64TB左右了。 当然这个大小是包括这个表的所有索引等其他相关数据。- 独享表空间
Innodb每个表的数据都保存在各自单独的文件中,这个时候的单表限制,又变成文件系统的大小限制了。 -
什么情况下才需要分表? 单表数量已经很大的情况下
-
union和union all的区别 UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作 UNION ALL 不会再对结果集进行去重操作
-
怎么查看sql语句中各个阶段所消耗的时间? 比如:排序时间 筛选时间?
- 使用 profiling 功能
- 执行 set profiling = 1 开启性能监控 (这样开启只会对当前会话有效)
- 执行 sql 语句
- 执行 set profiling = 0 关闭性能监控
- 执行 show profiles 来获取刚才sql语句的query id.
- 执行 show profile for query query_id 来查看sql语句的具体执行过程和消耗的时间。
- 使用 mysql 自带的 performance_schema数据库
- 如何用,还未知?
- 使用 profiling 功能
-
mysql自带数据库
- information_schema : 数据表的统计信息
- performance_schema : sql语句执行的性能监控信息
- 查看是否开启了性能监控功能
show variables like 'performance_schema';- 如何开启性能监控功能?未知
-
MySQL死锁示范 Client A | Client B — | —
(A) START TRANSACTION; |
(B) SELECT * FROM t WHERE i = 1 LOCK IN SHARE MODE; | | | (C) START TRANSACTION; | | (D) DELETE FROM t WHERE i =
1;
(E) DELETE FROM t WHERE i = 1; |-
(B) 的执行会让Client A获取一个i=1这一行的 共享锁
-
(D) 的执行会请求一个 i= 1 这一行的 排它锁,但要想获得这个排它锁,Client A必须先释放这一行的 共享锁
-
(E) 的执行会请求一个 i= 1 这一行的排它锁,但要想获得这个排它锁,Client B必须先释放这一行的 排它锁(尽管还没有获得)。
-
上面这个例子光看貌似不能产生死锁,但mysql认为就是死锁,这一点可以通过实验然后通过show engine innodb status查看,在idea控制台也能看到下面的输出
-
于是造成了Client B等待Client A释放锁,然后Client A又在等待Client B释放锁的局面,于是造成了 死锁。
- innodb解决这个问题的方法就是释放掉其中一个客户端占有的锁,并返回一条错误消息给这个客户端。
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
-
-
锁
- 表级锁 table-level lock
- 行级锁 row-level lock
- 共享锁 shared lock (S)
- 排它锁 exclusive lock (X)
- 意向锁 intention lock (是表级锁,表示该事务接下来会获取哪种类型的锁。)
- 意向共享锁 intention shared (IS) : 表示该事务接下来会获取共享锁。
- 意向排它锁 intention exclusive (IX) : 表示该事务接下来会获取排他锁。
-
查看MySQL死锁信息
show engine innodb status\G; 找到以下区域 ------------------------ LATEST DETECTED DEADLOCK ------------------------

- 随机毒鸡汤:每天提高的,不是我的成绩,而是我的发际线。