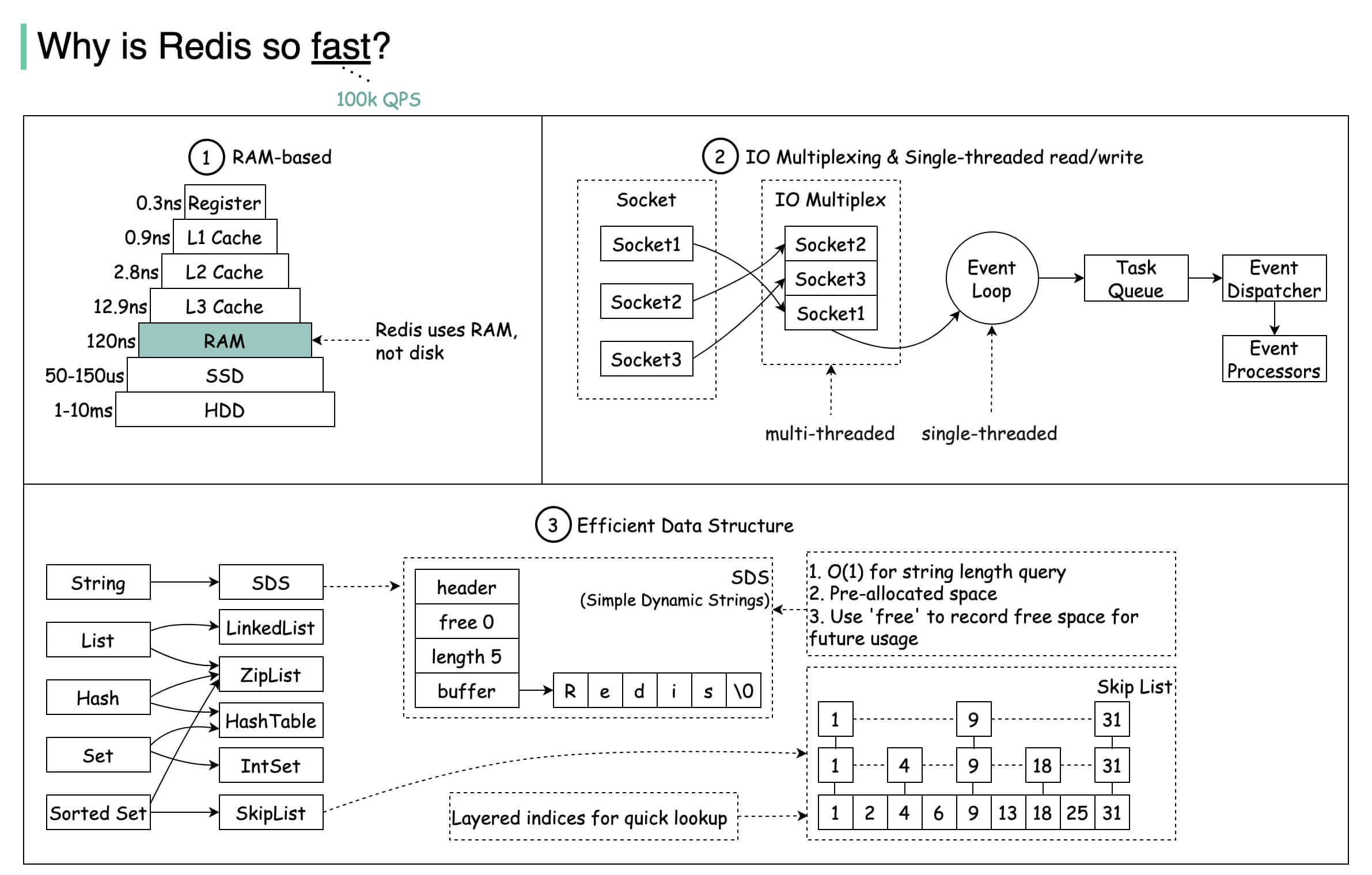
什么redis那么快
- 基于内存,内存的访问速度是磁盘的上千倍;
- 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
- 内置了多种优化过后的数据结构实现,性能非常高。
比如字符串并没有采用c原生字符串结构,而是采用了名为SDS的简单动态字符串结构,获取字符串长度的时间复杂度为O(1),而c语言里的字符串获取字符串长度需要O(n)
redis与 memcached的区别
5中常见数据结构
- string
redis中的string并没有采用c语言里的字符串,而是采用了一种名为SDS(simple dynamic string)简单动态字符串的结构。
获取字符串长度的时候,c语言里的字符串需要O(n)的时间复杂度,而sds只需要O(1)
- list
底层的数据结构是一个双向链表,可以理解为是java里的LinkedList
- hash
底层数据结构就是hash表嘛,可以理解为java里的hashmap,也是数组+链表
- set
无序集合,可以理解为java里的HashSet
- zset(sorted set)
相比set而言,增加了一个权重参数score,可以按照score进行排序,有点像java里的treeset
实际底层采用的数据结构是 跳表(skip table)
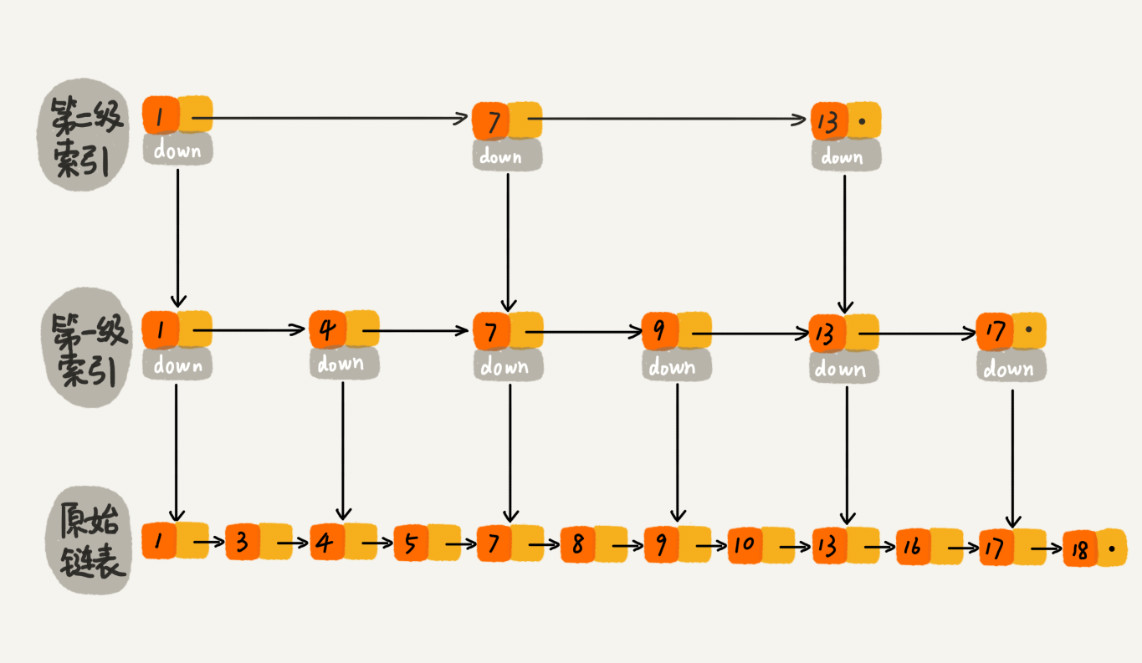
每两个节点向上抽取一个到上级构成索引,最终形成多级索引,时间复杂度为O(logn)
3中不常用数据结构
- bitmap
就是bit数组
- HyperLogLog
不懂,好像是拿来计数的
- geo
基于sorted set(zet)实现,将经纬度通过geohash算法转换为一个数字作为zset里的score,所以可以使用zset的相关命令
string与hash
这两个怎么选
- 存储相同数据情况下,string比hash更省空间
- hash可以对单个key进行各种操作,但string不行,所以这种情况下,hash需要传递的数据量更少,性能更高
- 如果对key需要频繁的单独更新,建议选择hash,其他情况可以选择string
比如购物车的场景,建议采用hash,因为可能频繁的更改商品数量等属性
redis的线程
-
最开始采用的是reactor的单线程模型,采用的网络io模型是多路复用
-
redis4.0版本为了处理一些大键值的删除操作,引入了多线程达到异步的效果

-
redis6.0版本在网络io方面也加入了多线程,来提高网络io的性能,采用的是reactor多线程模型(注意:对命令的执行还是单线程穿行执行)
redis刚开始为啥采用单线程?
- 单线程更加容易编程,方便维护
- 性能瓶颈不在是否采用cpu,而是在于内存和网络
- 引入多线程后编码相对复杂,并且还有引入新问题,比如线程的上下文切换等开销
redis6.0为何又引入了多线程
其实不是在redis6.0才引入多线程,redis在4.0版本的时候就已经引入了多线程,只不过引入多线程的目的是为了针对一些大键值对的删除操作,因为这样的一些操作相对比较耗时,所以为了不影响其他任务,引入了多线程。
而redis6.0中引入多线程的目的在于进一步提高网络io的读写性能,比如数据的编码、解码
需要注意的是:虽然redis6.0引入了多线程来提高网络io的读写性能,但在命令的执行上仍然是单线程顺序执行的
redis6.0的io多线程默认禁用的,通过参数 io-threads-do-reads 开启,再通过参数 io-threads 设置线程数,否则不生效
官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
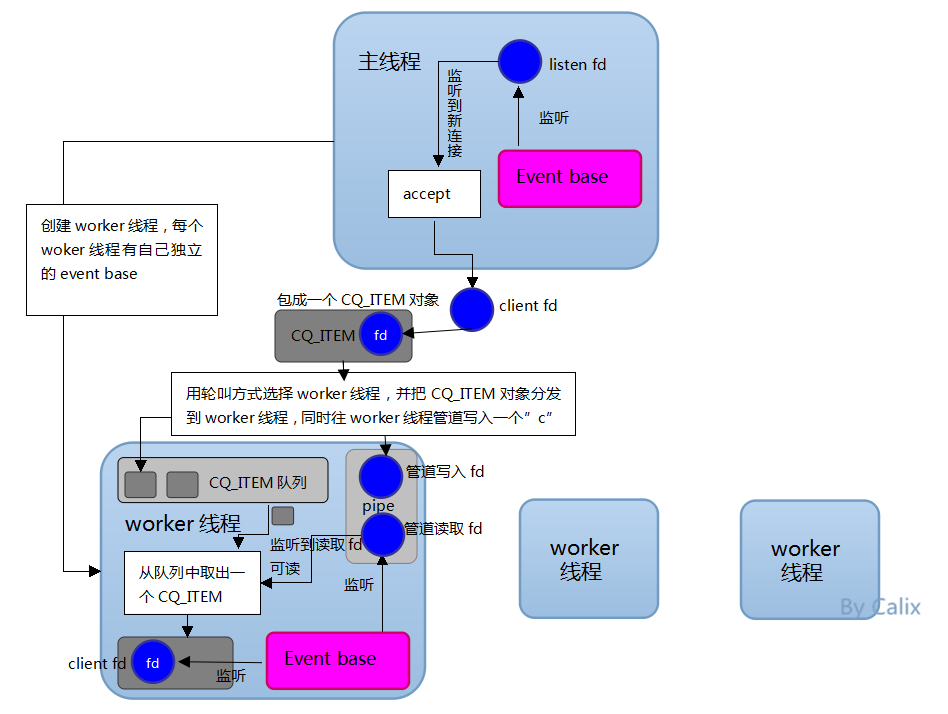
redis的线程模型
redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。 它采用 IO 多路复用机制同时监听多个 socket,根据 socket
上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket
产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。

为啥要设置过期时间
- 内存是有限的,不设置的话可能很快就会导致内存使用完,最终崩溃
- 很多时候,存储的内容并不需要一直存在
redis是如何判断某个key是否过期的?
redis内部有个过期字典,可以理解为hash表,这个字典的key指向了设置了过期时间的那个key,value就是这个key的过期时间,是一个unix的时间戳


如何删除过期数据的?
分为两种删除策略:
- 惰性删除
- 只有在对key进行某种操作的时候才会去检查是否过期,这样对cpu最友好,但有个问题就是可能会有一些过期的key并没有删除,仍驻留在内存中
- 定期删除
- redis会每隔一段时间抽取一批过期了的key进行删除
- 有了定期删除,但仍有可能会有一些过期key没有得到删除,或者内存不够用了,怎么办? 那就依赖redis的内存淘汰策略
Redis内存淘汰策略
-
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
-
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
-
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
-
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
-
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
-
allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
-
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
-
no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
lru:least recently used,最近最少使用的
lfu:least frequently used,最不经常使用的
持久化机制
- rdb:快照
- 会创建某个时间点内存的快照,可用于在重启或崩溃时恢复数据。
- 创建快照是会影响正常使用吗?redis提供了save和bgsave两个命令,save命令会阻塞主进程,bgsave不会,默认是bgsave。
- 可在配置文件中配置多组save来创建快照
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
- aof(append only file)
- 每次在执行更新操作的时候,都会把命令记录到aof缓冲中(主线程在负责写),然后通过appendsync配置来决定何时把缓冲中的内容落盘
- 相对rdb来说,因为记录的是命令流水,aof文件通常会比rdb文件大很多
- appendsync有三个参数(同步动作是由另外的线程负责):
- always: 每次执行更改操作都会进行落盘,这种方式可以保证不会丢失命令,但影响性能
- everysec: 每秒落盘一次,这种方式可能丢失命令,但对性能影响不大,算是1和3的居中方案
- no: redis程序不负责落盘,由操作系统来决定何时落盘,这种方式也可能丢失命令
aof重写
大概意思就是,由于aof记录的是命令流水,所以时间久了aof文件可能异常的大,通过aof重写能够缩写文件大小。 大致原理就是比如之前的aof有100条set命令,最终只保留一条,具体细节不知道
混合持久化
redis4.0开始提供了混合持久化,就是aof重写的时候会直接把rdb的内容写到aof文件的开头,这样做的好处就是结合了rdb和aof的优点,但可读性会变差
redis事务
相关四个命令:MULTI、EXEC、DISCARD、WATCH
> MULTI
OK
> SET USER "Guide哥"
QUEUED
> GET USER
QUEUED
> EXEC
1) OK
2) "Guide哥"
DISCARD就是放弃执行,注意不是回滚,redis的事务不支持回滚
redis的事务是把需要执行的命令放入一个队列中,当调用exec命令时候,则依次执行队列中的命令
WATCH: 在通过exec执行某个事务的时候,如果事务里的某个被watch命令监视的key被修改,那么整个事务都不会执行
> WATCH USER
OK
> MULTI
> SET USER "Guide哥"
OK
> GET USER
Guide哥
> EXEC
ERR EXEC without MULTI
事务对acid四个特性的支持: A: redis的事务不支持回滚,所以不支持A C: 不支持回滚,那当然不支持一致性 I: 由于命令的执行是单线程执行,所以不存在多个事务同时执行的情况,所以可以说支持隔离性吧 D:
有持久化的方案,可以说算支持吧
总结:
- 实际工作很少使用,不建议使用
- redis的lua脚本本质也不支持原子性,如果lua脚本中途执行错误,之前执行了的命令是不会撤销的,出错之后的命令不会继续执行
redis优化技巧(使用技巧)
- 能设置过期时间都尽量设置一下,避免内存快速消耗,设置引发更严重的后果
- 在存放value的时候,value尽量不要太大
- key字符串也尽量精简
缓存穿透
分两种情况:
- 请求了大量数据库中不存在的key,导致大量请求落到数据库身上。
- 请求了打了数据库中存在的key,但是此时这个key刚好过期或者其他原因导致缓存中没有数据,最终大量请求落在数据库身上。
第一种情况主要有两个方案:
- 缓存不存在的key
- 布隆过滤器
具体可以参考: 缓存穿透
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
第二种情况的解决方案:
- 分布式锁.
具体如下:
大量请求穿透缓存要去读数据库的时候,先上一个分布式锁,如果加锁不成功,则循环间隔时间读取缓存。
这个时候只有一个加锁成功,加锁成功这个请求读数据并更新缓存。
上面的做法可以进一步优化:本地锁和分布式锁配合使用。
假设两个jvm实例,现在又1000个请求都是请求同一个数据,分布落在两个jvm实例上,分别500个请求,如果在两个jvm实例上使用分布式锁,那么就会有1000个请求几乎同时
发起分布式锁。这其实没有必要。可以先在本地使用本地锁,这个每个jvm实例上顶多有1个请求拿到锁,然后在请求分布式锁,这样大大减小了分布式锁的请求量 也减少了网络传输量
- 不同的key设置不同的过期时间,避免同时失效
缓存雪崩
个人觉得缓存雪崩没有一个明确的定义,总的来说就是由于某些原因导致缓存不可用,这样大量请求打到后端db,引发一系列问题出来
从这个层面来说,缓存穿透也算缓存雪崩
还有就是比如集群下的redis,可能由于采用了不恰当的分片算法,但某个节点不可用时,导致整个redis集群不可用,最终请求到达db
缓存和数据库一致性
一般情况下我们都是这样使用缓存的:
先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
这种方式很明显会存在缓存和数据库的数据不一致的情况。
允许非严格一致性
下面的方案在读数据的时候,流程都是一样的:先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存
区别在于更新数据的时候:
-
先更新数据库,后删除缓存(不是更新,这种称之为 Cache Aside Pattern)
如果删除缓存失败,增加重试机制,也就是当网络可用或缓存服务可用的时候再次删除
-
先删缓存在更新数据库
-
先更新数据库,后更新缓存(是更新,不是删除)
上面三种方案各有优劣,没有谁一定比谁好,具体要看业务情况选择
严格一致性
就是读写请求要串行化,非常影响性能
读数据的时候,如果次数没有请求要更新缓存,则尝试走缓存;如果发现有请求要更新缓存,则等待那个请求完成再走缓存。
走缓存的逻辑:
如果缓存有数据,则直接返回;如果没有,则先标识自己要更新缓存,如果标识成功,则读数据库并更新缓存。
如果标识不成功,则等待标识成功的请求完成再读缓存。
可以参考:https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md
这个网址作为一个参考,个人觉得描述有点繁琐。
-
Redis键过期策略
-
定期删除
-
惰性删除
-
redis 高可用方案
- codis
- 自带的cluster方案
- Twemproxy
twitter的

保证高可用
- 首先尽量保证redis集群的本身的高可用【采用合适的分片算法、还可以做master/slave这些,以及合适的持久化方案】
- 万一还是挂了,启用限流,保证后端的db不会挂掉,同时尽快恢复redis集群
redis分布式锁
- redlock: 是一种算法,全名叫做 Redis Distributed Lock;
大概意思有点想raft算法,就是要绝大多数节点加锁成功才算加锁成功
- redission:封装了java版本的redlock算法,也支持单个redis节点
万一服务挂了,后台有个线程会一直给当前锁续期,默认的ttl是30s,看门狗会每隔10秒就续期一次

redis限流器
s
一致性hash
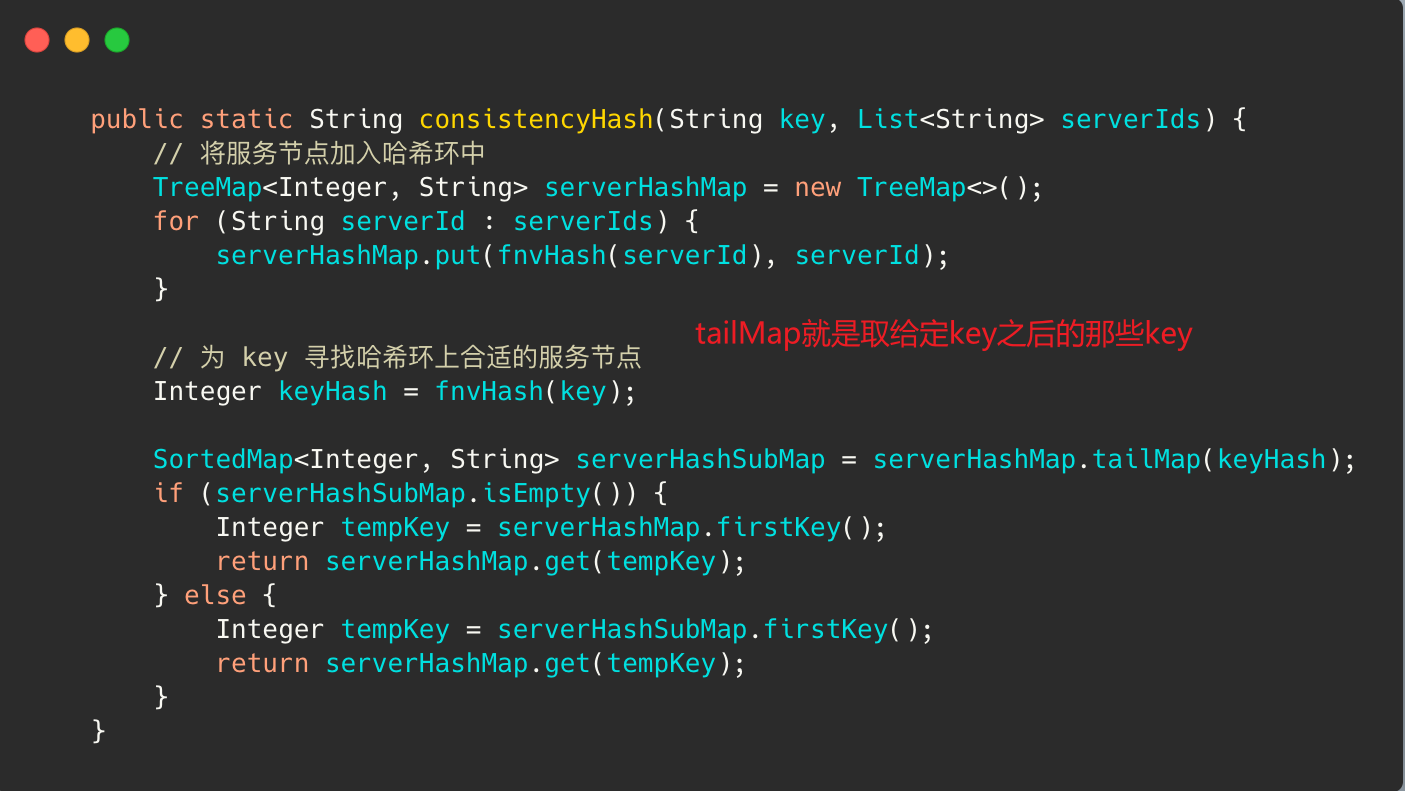
采用 FNV-Hash 算法,这种算法的特点是:能快速hash大量数据并保持较小的冲突率。
它的高度分散使它适用于hash一些非常相近的字符串,比如URL,hostname,文件名,text,IP地址等。
限流算法
- 固定窗口(计数法)
- 滑动窗口
- 漏桶
可以想象为java里的队列,队列的容量有限,队列满了则拒绝执行,请求进来先排队,然后系统从队列里取出请求进行处理
比如可以用一个aop实现,接收到请求后,信号量减一,初始信量化是1w,就相当于桶的容量,每处理完成一个请求,则加一(可以用redis中的加加减减实现) - 令牌桶
和漏桶有点像,具体aop的逻辑是:
接收到请求后,信号量减一,请求处理完成不加一,而是由另外一个线程已固定的速率增加信号量(这个地方用信号量可能不恰当,但可以理解为redis中的加加减减)
漏桶与令牌桶
- 漏桶是已固定的速率处理请求,至于请求进来的速度没有限制,只要桶还有容量,不过可以稍微修改下不以固定速率处理请求,而是能处理多块就多块
- 令牌桶是以固定的速率生产令牌,处理请求必须先获得令牌,令牌桶貌似可以理解为倒着的漏桶,漏桶是固定速率出水,令牌桶是固定速率进水
- 令牌桶是以恒定速率创建令牌,但是访问请求获取令牌的速率“不定”,反正有多少令牌发多少,令牌没了就干等。而漏桶是以“恒定”的速率处理请求,但是这些请求流入桶的速率是“不定”的。
- 漏桶的天然特性决定了漏桶后面的系统不会发生突发流量,这个既是优点又是缺点,优点就是后面的系统不会有突发流量,缺点就是一些
上面的限流算法都是一个理论,具体实现可能和理论并不一致,也就是可能具体的实现既有漏桶的影子,也有令牌桶的影子。
扩展阅读:
- https://blog.csdn.net/weixin_41846320/article/details/95941361
- https://www.jianshu.com/p/88ff90519ab1
- 随机毒鸡汤:为什么要晒这么黑?因为我不想白活一生。