总览
hadoop由两位大佬创建,起初他们是在贡献于apache nutch项目(一个网络爬虫项目),这个项目会会涉及到两个问题:
- 大数据量的存储
- 大数据量的处理分析
于是诞生了hadoop这个项目。名字来源于其中一个大佬儿子的一个大象玩具
主要包含下面三个组件:
- HDFS,hadoop distributed file system. 用于存储大量数据
- MapReduce 用来处理分析大量数据,核心思想就是分而治之。
- YARN hadoop集群管理框架,任务调度框架
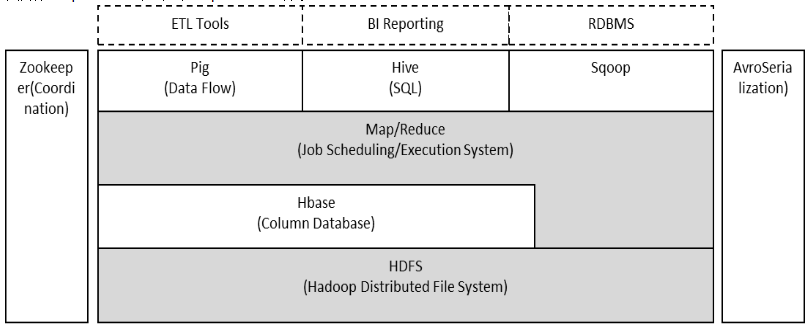
MapReduce
核心思想:分而治之
是一个离线数据计算框架,不能处理实时数据
可以粗滤分为两个阶段:
- map阶段
- reduce阶段
在Map阶段中,输入数据被分割成多个小块,然后并行地对每个小块应用Map函数,生成一组中间键值对。在Reduce阶段中,所有具有相同键的值都被收集到一起,然后对这些值应用Reduce函数,以生成最终结果。
一个比较形象的语言解释MapReduce:
要数停车场中的所有停放车的总数量。
你数第一列,我数第二列 …这就是Map阶段, 人越多,能够同时数车的人就越多,速度就越快。
数完之后,聚到一起,把所有人的统计数加在一起。这就是Reduce合并汇总阶段。

Docker安装hadoop
这里假设已经有一台centos服务器,并已经安装docker和docker-compose。版本如下:
➜ ~ docker -v
Docker version 24.0.6, build ed223bc
➜ ~ docker-compose -v
Docker Compose version v2.21.0
准备docker-compose.yaml文件,内容如下:
version: "3"
services:
namenode:
image: apache/hadoop:3.3.6
container_name: namenode
hostname: namenode
command: ["hdfs", "namenode"]
ports:
- "50070:50070"
- "8020:8020"
env_file:
- ./config
environment:
ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name"
datanode:
image: apache/hadoop:3.3.6
container_name: datanode
command: ["hdfs", "datanode"]
ports:
- "50010:50010"
- "50075:50075"
- "50475:50475"
- "50020:50020"
env_file:
- ./config
resourcemanager:
image: apache/hadoop:3.3.6
container_name: resourcemanager
hostname: resourcemanager
command: ["yarn", "resourcemanager"]
ports:
- 8088:8088
- 8033:8033
env_file:
- ./config
volumes:
- ./test.sh:/opt/test.sh
nodemanager:
image: apache/hadoop:3.3.6
container_name: nodemanager
command: ["yarn", "nodemanager"]
env_file:
- ./config
准备config文件,内容如下:
HOST_IP=localhost
CORE-SITE.XML_fs.default.name=hdfs://namenode
CORE-SITE.XML_fs.defaultFS=hdfs://namenode
HDFS-SITE.XML_dfs.namenode.http-address=namenode:50070
HDFS-SITE.XML_dfs.namenode.rpc-address=namenode:8020
HDFS-SITE.XML_dfs.permissions.enabled=false
HDFS-SITE.XML_dfs.datanode.http.address=0.0.0.0:50075
HDFS-SITE.XML_dfs.datanode.https.address=0.0.0.0:50475
HDFS-SITE.XML_dfs.datanode.address=0.0.0.0:50010
HDFS-SITE.XML_dfs.datanode.ipc.address=0.0.0.0:50020
HDFS-SITE.XML_dfs.datanode.hostname=${HOST_IP}
HDFS-SITE.XML_dfs.replication=1
YARN-SITE.XML_yarn.resourcemanager.hostname=${HOST_IP}
YARN-SITE.XML_yarn.resourcemanager.webapp.address=resourcemanager:8088
YARN-SITE.XML_yarn.resourcemanager.admin.address=resourcemanager:8033
YARN-SITE.XML_yarn.nodemanager.pmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.delete.debug-delay-sec=600
YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-applications=10000
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-am-resource-percent=0.1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.queues=default
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.maximum-capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.state=RUNNING
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_submit_applications=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_administer_queue=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.node-locality-delay=40
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings=
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings-override.enable=false
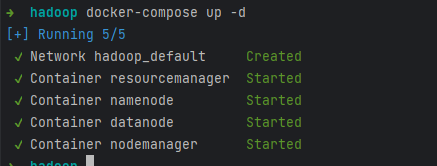
上面两个文件都放在同一个目录下,然后在目录中执行:
docker-compose up -d
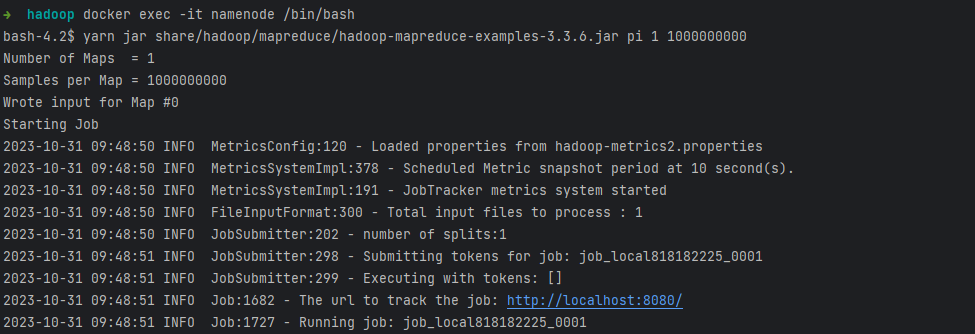
进入namenode节点:
docker exec -it namenode /bin/bash
在namenode节点执行:
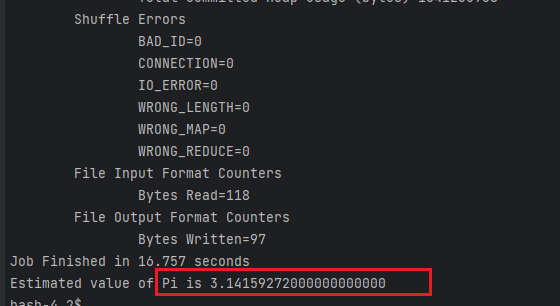
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 1 1000000000
- pi :表示进行圆周率计算
- 1 :并发数,这里配置原因,我这边调低点,设置为1
- 1000000 : 这个是样本数,越大计算出来的pi值越准确
- 随机毒鸡汤:世上最远的距离不是生与死,而是这道题,我好像在哪里见过。