InnoDB索引
InnoDB支持的索引
-
分类方式1:
-
B+树索引
- B 不是指binary,而是balance。
- 由平衡二叉树演变而来,是目前关系型数据库中查找最为常用和有效的索引
- InnoDB中,通过某个键值找到value不是具体的数据行,而是数据行所在的页,然后读取页到内存,再在内存中进行查找,最终找到要查找的数据。
-
全文索引
-
哈希索引
InnoDB支持的哈希索引是自适应的,InnoDB存储引擎会根据表的使用情况自动为表生成哈希索引,不能人为干预是否在一张表中生成哈希索引。
-
-
分类方式2:
-
聚集索引
-
辅助索引
-
-
分类方式3:
-
主键索引
-
唯一索引
-
覆盖索引
-
联合索引 == 复合索引
-
B+树索引
前面提到过,页是MySQL进行IO操作的最小单位(表段区页,每页16kb,每次申请4-5个区,每个区1m)
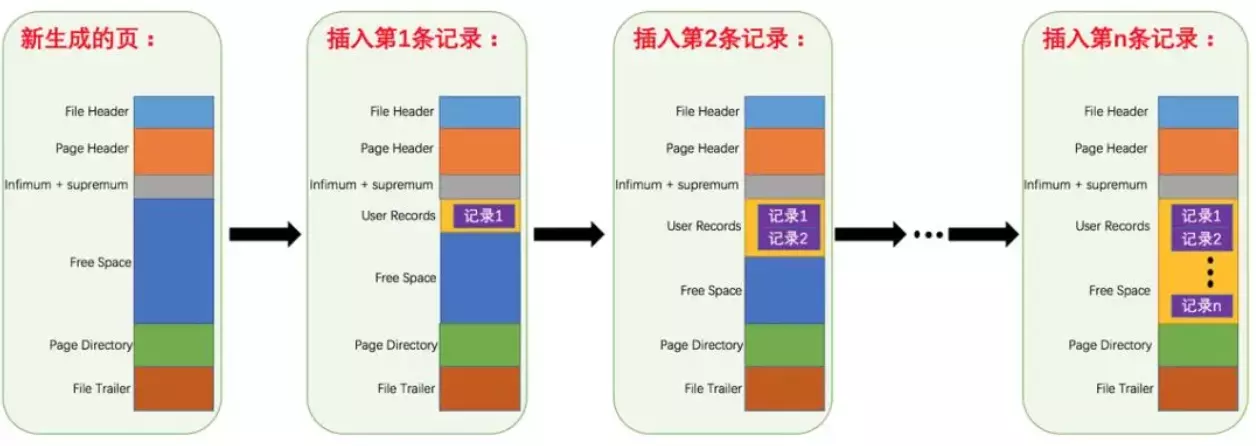
页的存储结构如下:


-
各个数据页组成一个双向链表
-
每个数据页中的记录又可以组成一个单向链表
-
每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
-
以非索引列作为搜索条件:依次遍历单链表中的每条记录
B树和B+树的区别
-
B数
-
关键字集合分布在整颗树中;
-
任何一个关键字出现且只出现在一个结点中;
-
搜索有可能在非叶子结点结束;
-
不支持范围查找

-
-
b+树相比于b树的查询优势:
-
b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
-
b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
-
对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历,如下两图:
-
-
-
B数
-
关键字集合分布在整颗树中;
-
任何一个关键字出现且只出现在一个结点中;
-
搜索有可能在非叶子结点结束;
-
-
b+树相比于b树的查询优势:
-
b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
-
b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
-
对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历,如下两图:
-
-
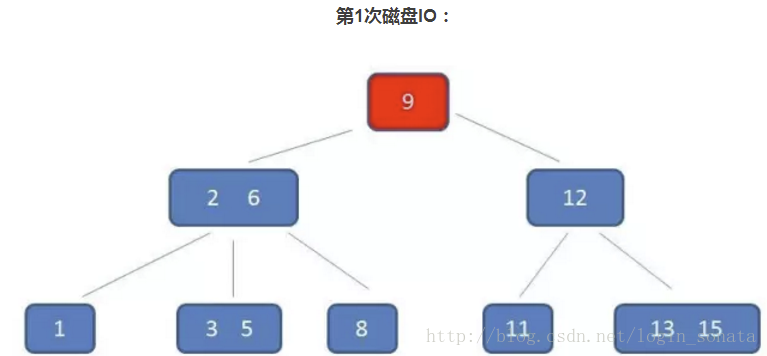
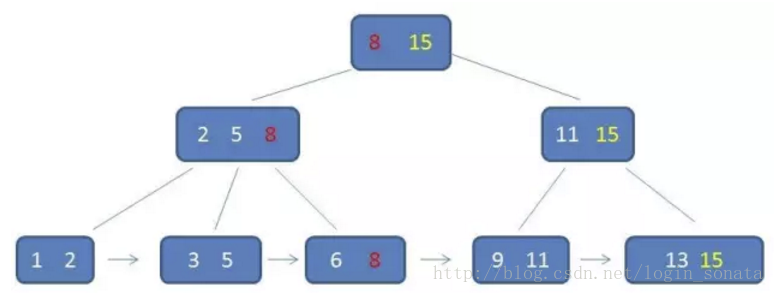
索引如何提高检索速度
有了上面的基础,我们来看看要找到id为8的记录简要步骤:
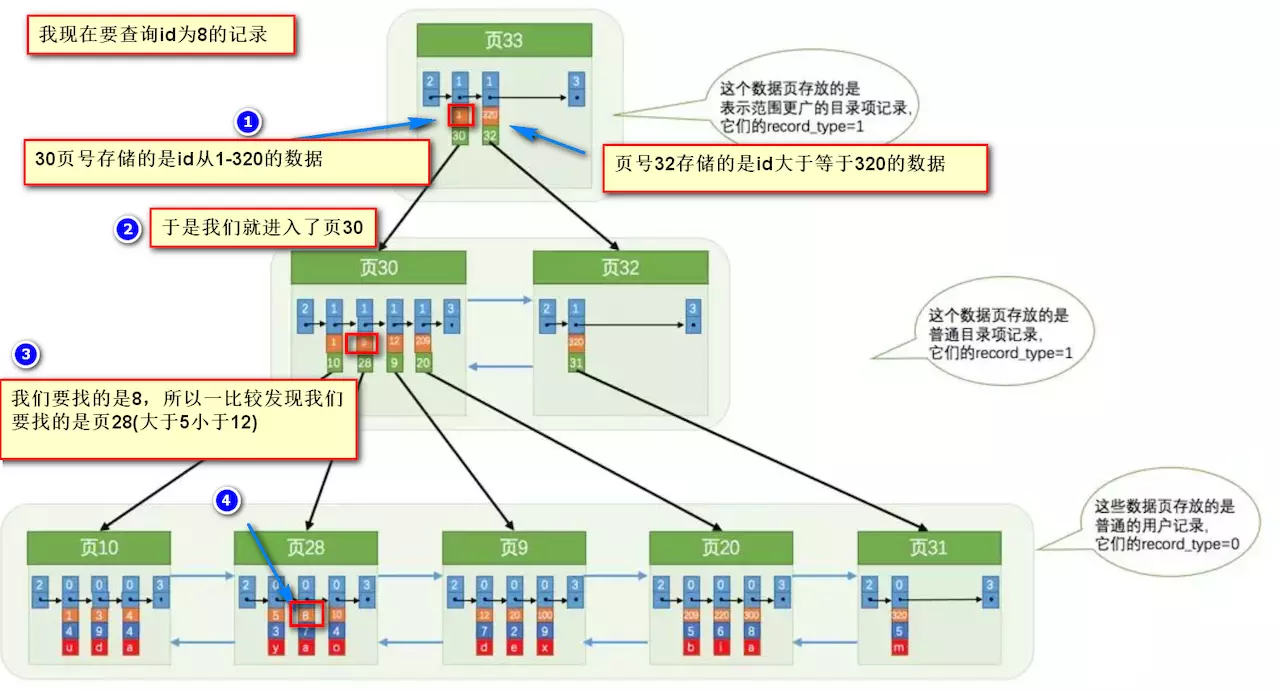
很明显,如果不使用索引就得遍历所有的数据知道找到目标数据。
关于MySQL中B+树索引更详细的资料参见:MySql中的B+树索引
索引如何降低增删改的速度
索引采用的结构是B+树,而我们知道B+树是平衡树的一种,对数据库执行增删改操作的时候,是会破坏平衡树的特点的,如果不采取额外的操作,B+树就可能退化成链表。因此在执行增删改操作的时候,必须采取额外的操作来维护B+树的特点,而这些额外的开销就降低了增删改的速度
-
平衡树
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。 -
B+树的具体算法参见:https://www.cnblogs.com/wade-luffy/p/6292784.html
Hash索引
主流的还是使用B+树索引比较多,对于哈希索引,InnoDB是自适应哈希索引的(hash索引的创建由InnoDB存储引擎引擎自动优化创建,人工干预不了)!
聚集和非聚集索引
聚集索引:以主键创建的索引
非聚集索引:以非主键创建的索引
一张Innodb引擎的表只能创建一个聚集索引(如果创建表的时候没有指定主键列,InnoDB会自动为每行数据生成一个6字节的rowid,并以此作为主键)
区别:
- 聚集索引在叶子节点存储的是表中的数据
- 非聚集索引在叶子节点存储的是主键和索引列,所以使用非聚集索引一般还需要做回表操作
- 聚集索引一张表只能创建一个,而非聚集所以一张表可以创建多个
回表:使用非聚集索引查询出数据时,拿到叶子上的主键再去查到想要查找的数据,拿到主键再查找这个过程叫做回表。
非聚集索引 == 二级索引 == 辅助索引
面试题
- 使用索引为什么可以加快数据库的检索速度啊?
- 为什么说索引会降低插入、删除、修改等维护任务的速度。
- 索引的最左匹配原则指的是什么?
- Hash索引和B+树索引有什么区别?主流的使用哪一个比较多?InnoDB存储都支持吗?
-
哈希索引没办法利用索引完成排序
-
不支持最左匹配原则
-
在有大量重复键值情况下,哈希索引的效率也是极低的—->哈希碰撞问题。
-
不支持范围查询
-
- 聚集索引和非聚集索引有什么区别?
-
聚集索引在叶子节点存储的是表中的数据
-
非聚集索引在叶子节点存储的是主键和索引列,所以使用非聚集索引一般还需要做回表操作
-
聚集索引一张表只能创建一个,而非聚集所以一张表可以创建多个
-
以上内容部分摘录自:https://juejin.im/post/5b55b842f265da0f9e589e79
- 随机毒鸡汤:知道螃蟹为何一直横着走吗?因为它有钱(钳),所以它任性啊!